
Zero-Trust in the Age of Inference: Fighting the Multi-Million Dollar API Bill
As production deployments transition from simple chat interfaces to thousands of autonomous, background-running agents, engineering teams are waking up to a terrifying new reality: Inference spend is the new cloud infrastructure tax.
In legacy cloud computing, infrastructure costs scaled predictably with user traffic. In the era of autonomous agents, a single unhandled logical loop or an unoptimized data extraction pipeline can rack up thousands of dollars in LLM API fees before an automated alert even triggers.
Moving beyond basic rate-limiting requires implementing Zero-Trust LLM Orchestration—an architecture that treats every model call, prompt expansion, and background agent context loop as an unverified execution threat to the company’s bottom line.
1. The Financial Vulnerabilities of Agentic Workflows
When agents are granted the autonomy to read code, fetch context, and execute multi-step tool calls, they introduce two primary financial failure modes:
The Recursive Tool-Loop Trap
Consider an agent tasked with syncing data between an external API and an internal database. If the external API introduces a minor schema mutation that the agent’s parsing logic fails to interpret, the agent may not simply throw an error. Instead, relying on its internal reasoning loop, it may repeatedly rewrite the payload, retry the execution, and re-query the model to “self-heal.” If left unchecked, this recursive loop can burn through millions of output tokens in minutes.
Context Window Exploitation
Modern long-context models allow developers to pass entire repositories or databases into a single prompt. While technically impressive, it is an architectural anti-pattern for cost-sensitive production applications. Passing a $3\text{MB}$ payload through an LLM to extract a single string value results in massive token waste. When multiplied across millions of production requests, this brute-force approach leads to severe margin erosion.
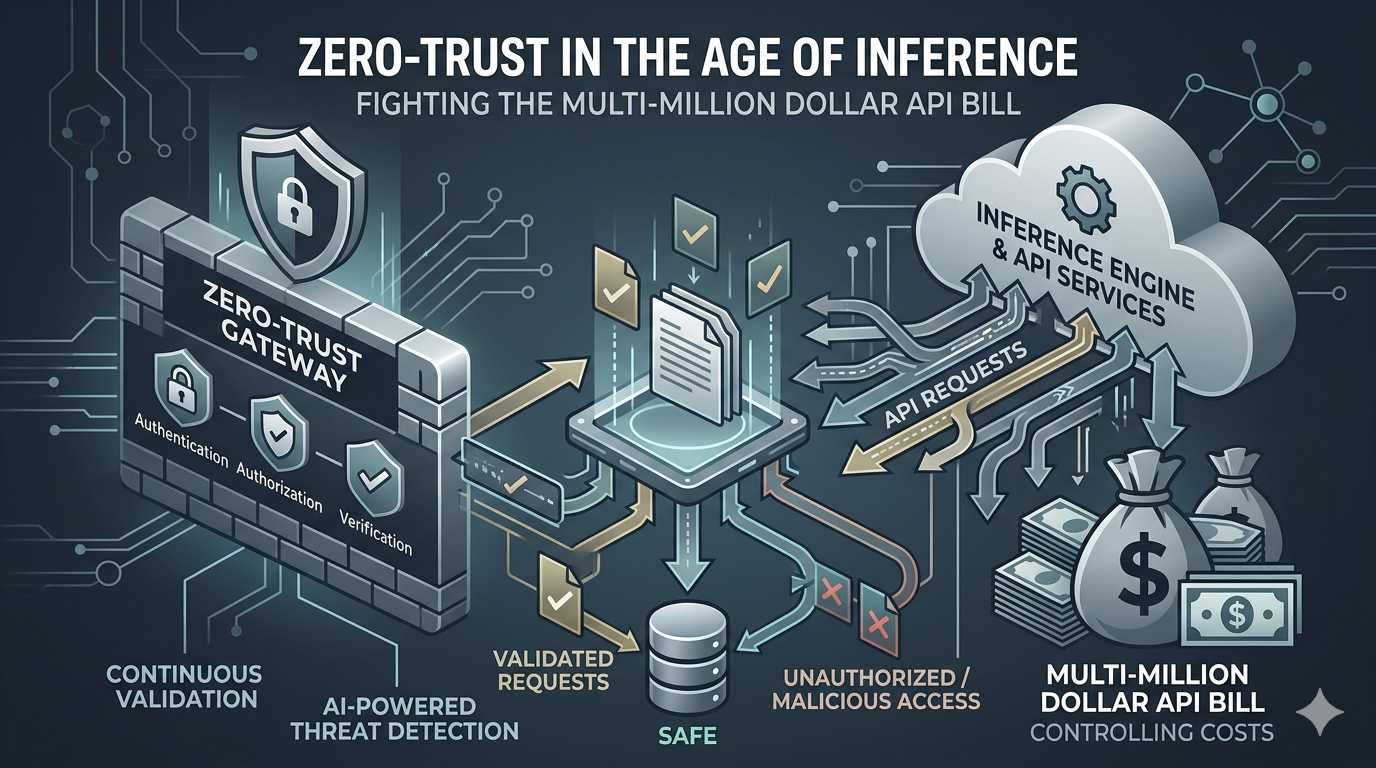
2. Blueprint for a Zero-Trust LLM Gateway
To neutralize these risks, teams must decouple their application logic from direct model access by deploying an independent, policy-enforced LLM Gateway between their core application workers and external model providers.
[Agent App] ➔ [Token Quarantine Proxy] ➔ [Semantic Cache Guard] ➔ [Upstream LLM Provider]
Component A: The Token Quarantine Proxy
Every request destined for an external model provider must pass through a proxy layer that enforces hard, stateful execution budgets per context block and agent session.
-
Deterministic Circuit Breakers: If an agent’s session exceeds a pre-allocated token limit or hits an unusual frequency spike (e.g., more than 50 execution steps within a single task), the proxy trips a circuit breaker, freezing the agent’s execution context and flagging it for human review.
-
Granular Cost-Centric Routing: The proxy reads the incoming prompt’s payload and routes it dynamically. Simple data formatting or structure validation tasks are stripped from expensive frontier models and redirected to highly optimized, cost-effective local open-source models.
Component B: The Semantic Cache Guard
The most cost-effective token is the one you never send upstream. A zero-trust gateway routes all inbound prompts through a low-latency vector cache layer to catch redundant queries.
-
Approximate Matching: Instead of relying on strict keyword equivalence, the cache evaluates the semantic vector distance of incoming prompts. If an agent asks a question or formats a chunk of text that closely mirrors a task executed five minutes prior, the gateway returns the cached response, reducing upstream API usage to zero.
3. Designing for Maximum Token Efficiency
Beyond implementing a gateway, software architects must build guardrails directly into their underlying data pipelines to optimize data ingestion for downstream inference.
| Optimization Vector | Anti-Pattern | Zero-Trust Standard |
| Data Ingestion | Passing raw HTML or unparsed document files straight to the prompt. | Forcing data through structured pre-processors (like markdown linters) to strip semantic noise before the inference step. |
| Context Assembly | Expanding agent context with blind, top-k vector searches that include irrelevant text chunks. | Employing multi-stage re-ranking pipelines to pass only the exact text fragments required to complete the task. |
| Schema Generation | Relying on multi-shot textual prompts with heavy examples to guide model output format. | Utilizing strict JSON-schema enforcement at the engine level to achieve perfect output formatting on the very first shot. |
4. The Path to Sustainable AI Operations
Uncapped, unmonitored access to frontier LLM APIs is the technical debt of the mid-2020s. As engineering teams shift from building prototypes to scaling automated enterprise platforms, financial governance must match technical execution.
Implementing a zero-trust architecture around inference workflows ensures that your software remains autonomous, resilient, and, above all, profitable. The goal is simple: let your agents operate with absolute freedom within your software ecosystem, but keep them on a strict, unbreakable financial leash.
editor's pick
latest video
news via inbox
Nulla turp dis cursus. Integer liberos euismod pretium faucibua